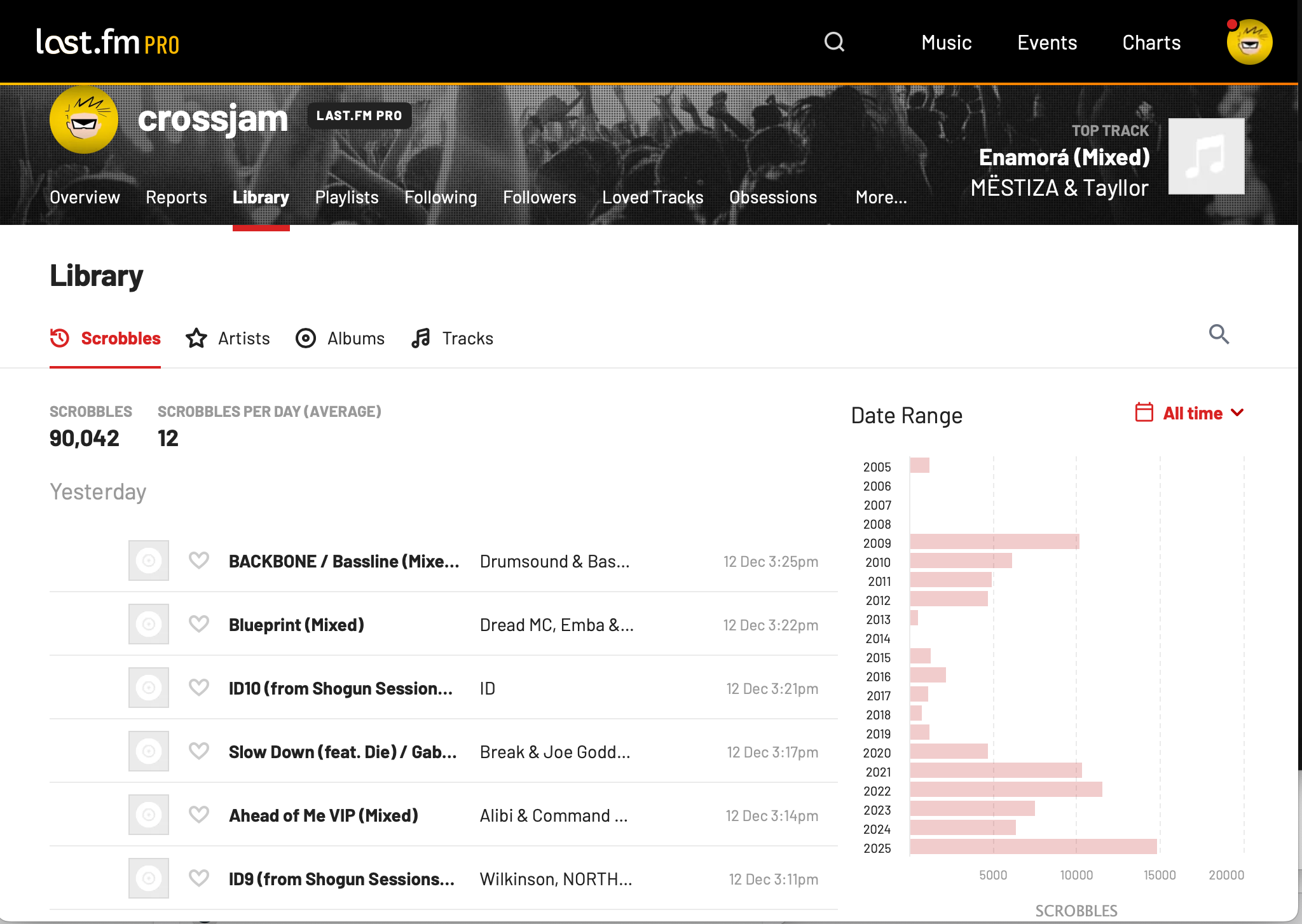
I recently reached 90,000 scrobbles recorded on last.fm! That spans a little over 20 years 😲 — roughly 4,500 per year, approximately 12 tracks a day. Depending upon the style of music, that’s easily 1 complete CD / album / mix a day, every day, for 20 years.
Let’s dig in a bit …
Okay, observant folks will notice a few gap years. Still, it’s impressive that a Web 2.0 poster-child service has managed to stick around this long. Using my scrobbledb side project, I was able to download all 90,000 scrobbles to a local SQLite database (27 MB in size if you’re curious).
The key reason I was able to do this is that last.fm, while still a going concern after 20+ years, has managed to maintain its API for all that time. But the last.fm API does have a curious design point. I did some minimal exploration of the data in the terminal console and discovered that the API eschews user-accessible unique IDs in the endpoints!
If you take a peek at the docs for the track.getInfo endpoint, the query is driven by the required artist name and track name arguments. user.getRecentTracks is the primary way to access a user’s historical scrobble record. The API response doesn’t include a UID for the scrobbles. Based on some sleuthing on my profile web pages, I’m pretty sure a UID exists, but it’s definitely not meant to be available to end users. Other endpoints behave similarly.
This could be an artifact of when the API was developed. Alternatively, I could see it being a conscious design choice. Scrobbles are self-reported data, often from dubious sources: dodgy file metadata, janky scrobbling clients, and iffy app plugins. Not attempting to consistently resolve that data would be a prudent design choice, and it wouldn’t surprise me.
Apparently, last.fm does integrate MusicBrainz data if entity information can be resolved to an entry within that database, so some of the data I downloaded includes MBID identifiers for tracks and albums. Time to do some exploratory data analysis and find out what percentage is covered.
My scrobble data might be out of the norm, if not a full-on outlier. I listen to a lot of DJ mixes. There are lots of remixes, renames, alternative versions, and DJ private white-label releases with little public information. Track titles, albums, and artists are often quite mangled. Playlists on Apple Music from live sets, which I’ve been bingeing, exacerbate the issue.
Ultimately, I’d like to build an interactive, AI-driven exploration app on top of this data. It looks like there are some data-integration challenges to address first; this might be a job for vector search.